\(\mathbb{P}(p_A > p_B | Y = y)\): in words, is the chance of success of A greater than B, given the data?
Modify the code below to approximate that probability.
source("../../solutions/simple.R")set.seed(1)bivariate =function() { p_A =simulate(Beta(1, 1))observe(1, Binom(size =1, prob = p_A)) # add the part of the model describing p_B (prior and likelihood) return # what is the "test function"?}posterior(bivariate, 10000)
Let us get more insight on joint posterior distributions (posterior over two variables).
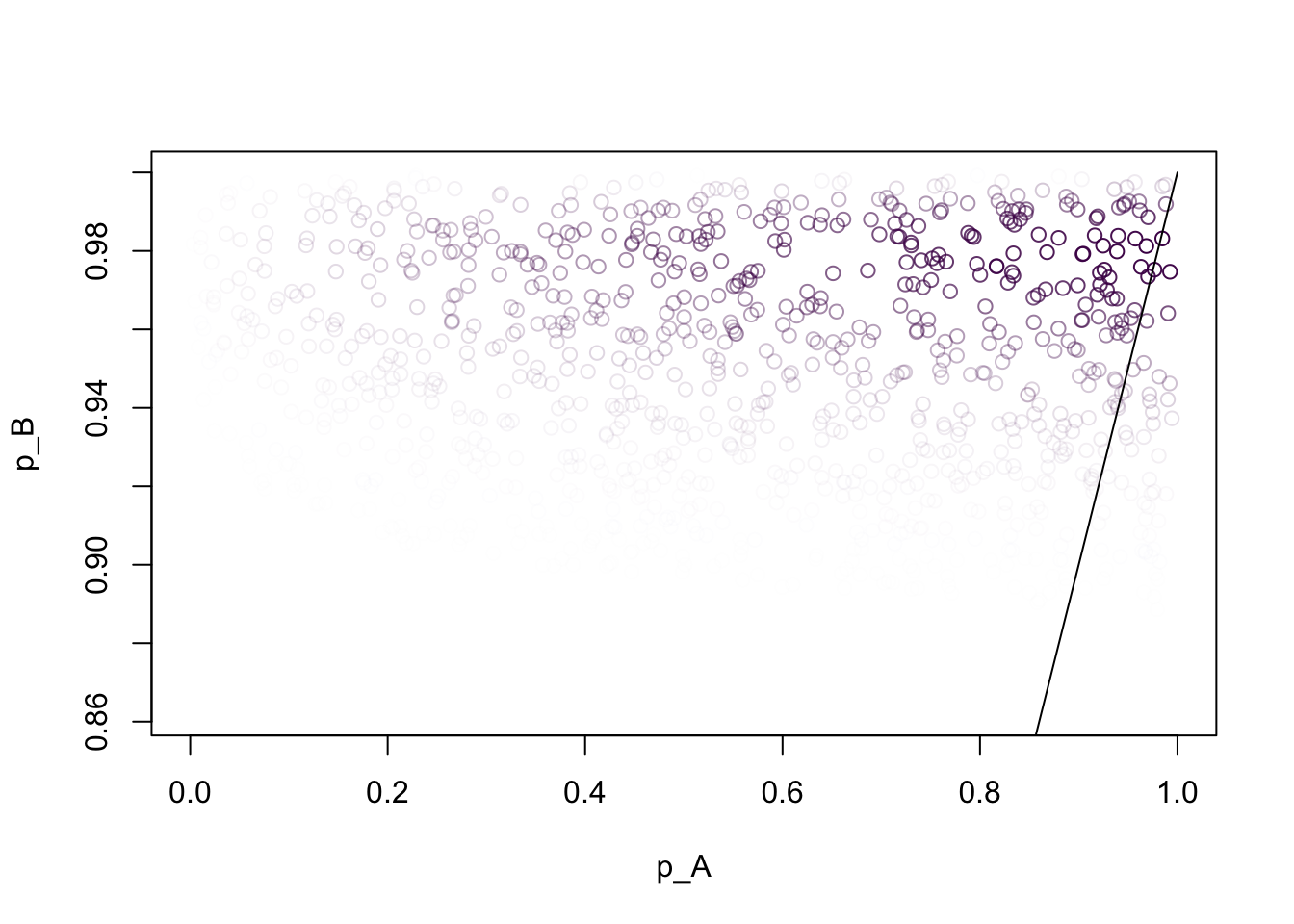
To do so, we use visualizations where the x-axis is the first parameter (here \(p_A\)) and the y-axis is the second parameter (here \(p_B\)).
# This contains useful functions to visualize the output of simPPLe:source("../blocks/simple_utils.R")source("../../solutions/simple.R")bivariate_pair =function() { p_A =simulate(Beta(1, 1))observe(1, Binom(size =1, prob = p_A)) p_B =simulate(Beta(1, 1))observe(98, Binom(size =100, prob = p_B)) # We modify the above to return a vector containing both parametersc(p_A, p_B)}# To compute the plot, we need the list of samples and weights ("particles"), i.e. more details compared to posterior()# This is what posterior_particles accomplishesparticles =posterior_particles(bivariate_pair, 10000)# Now we use these to create the plot belowweighted_scatter_plot(particles, plot_options =list(xlab="p_A", ylab="p_B"))xaxis =seq(0, 1, 0.01)lines(xaxis, xaxis)
Each point is a sample produced by SNIS, \(x^{(m)}= (p_A^{(m)}, p_B^{(m)})\).
We encode its associated weight \(w^{(m)}\) by the transparency (alpha) of the point.
Question: What region of integration should you use to compute \(\mathbb{P}(p_A > p_B | Y = y)\)?